Me parecen excepcionales los dos artículos que comenta telendro estos días sobre el funcionamiento de Google.
Me parecen excepcionales los dos artículos que comenta telendro estos días sobre el funcionamiento de Google.
El primero de ellos, Sandbox como filtro bayesiano menciona un artículo de iConsulting en el que se compara el Sandbox de Google con el funcionamiento de un filtro bayesiano. El resumen es que Google no filtra sitios web con su Sandbox, sino que filtra resultados de búsqueda dada una consulta.
El segundo, Número de resultados para cierta búsqueda, de algo que estos días estaba yo también dándole vueltas, es el porqué de que aparezcan tanta cantidad de resultados (más de 40.000) para una búsqueda que es prácticamente imposible que tenga más de 1.000. La fórmula secreta (no sé cómo la habrá conseguido, pero es excepcional) de cómo se calcula eso:
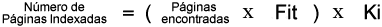
Fit: Factor de incremento temporal
Valor asociado a la curva de incremento de resultados de una búsqueda concreta. Si en un espacio corto de tiempo aparecen muchos resultados (nuevos o no) para cierta búsqueda, Google corregirá con este factor la velocidad de indexación.
Ki: Constante de inflado.
Se multiplica todo por una constante para que quede claro cual es el buscador que más resultados ofrece.
Por eso: Número de resultados = (762 x 52) x 1,113 = 44.100
He de reconocer que al menos se están sacando datos provechosos, sean verdad o mentira… al menos salen ideas…
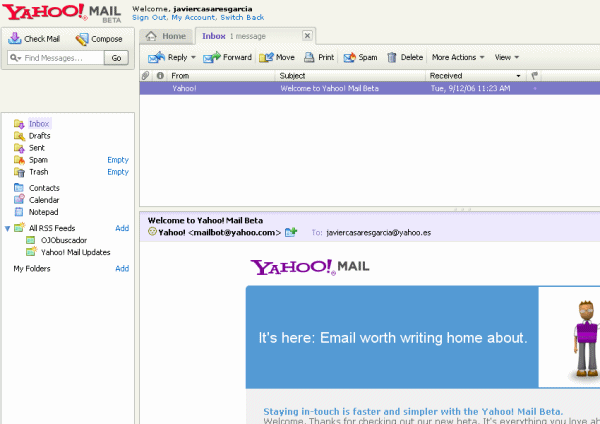
 A mediados de Julio me enviaron un mensaje de correo electrónico para poder tener la nueva versión beta de Yahoo! Mail y, no sé si es que ya está disponible para todos, pero, hoy he entrado y me ha dejado activar la nueva interfaz (también es posible que el haber entrado por mail.yahoo.com haya tenido algo que ver).
A mediados de Julio me enviaron un mensaje de correo electrónico para poder tener la nueva versión beta de Yahoo! Mail y, no sé si es que ya está disponible para todos, pero, hoy he entrado y me ha dejado activar la nueva interfaz (también es posible que el haber entrado por mail.yahoo.com haya tenido algo que ver).