Qué hace falta para personalizar un servicio de búsquedas para dispositivos móviles es lo que está presentando Ben Bratu de Motorola Labs.
Una de los primeros retos que plantea es el del hardware, ya que ha de estar todo preparado para tener soporte por todos los dispositivos, y eso es algo complejo, además de encontrarse problemas con las redes y sus tecnologías, ya que hay muchas y para muchos tipos de dispositivos. Los proveedores de contenido y las propias aplicaciones también han de decir mucho.
Con respecto a la personalización, hay que generar un contexto para el usuario, en base a las aplicaciones y contenidos, además de factores como tiempo y espacio.
Lo que queda claro (después de muchos recursos técnicos) es que el tipo de búsquedas ha de ser diferentes a las de web, y que hay que tener contenidos diferentes para las versiones móviles, muy enfocado a metadatos.
 Uno de los proyectos más interesantes que tenía ganas de ver es el de Polar Rose, tecnología de reconocimiento de imágenes que he podido ver por primera vez hoy de una forma más interna.
Uno de los proyectos más interesantes que tenía ganas de ver es el de Polar Rose, tecnología de reconocimiento de imágenes que he podido ver por primera vez hoy de una forma más interna.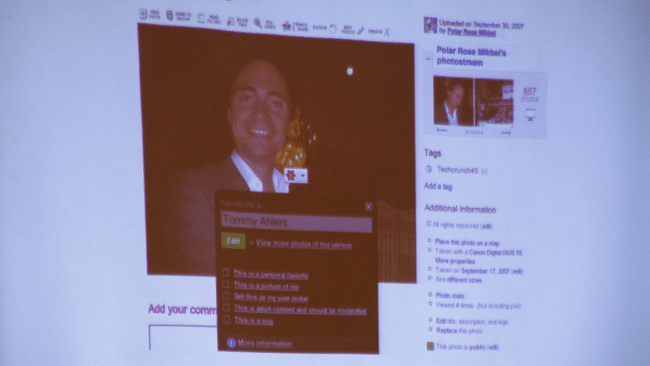

 Ahora es la ocasión de Julien Law-To de
Ahora es la ocasión de Julien Law-To de  Ya estamos aquí… digo estamos porque he visto caras conocidas como la de nuestro compañero José Agüera y la de
Ya estamos aquí… digo estamos porque he visto caras conocidas como la de nuestro compañero José Agüera y la de